Random Forest - All you need to know.

I am an aspiring data scientist who is also a full-stack python developer and I love to share my learnings with others. I love to work on exciting projects and keen to learn new technologies. I’m now trying to solve women’s issues — including the wage gap and sexual harassment and most importantly equality.
What is Random Forest:- Random forest is an ensemble machine-learning algorithm, which is capable to perform classification and regression both by using multiple decision tree commonly known as bagging.
The basic idea behind this is to combine multiple decision trees in determining the final output rather than relying on individual decision trees. Random Forest has multiple decision trees as base learning models. We randomly perform row sampling and feature sampling from the dataset forming sample datasets for every model. This part is called Bootstrap.
let's quickly go over decision tree as they are the basic building block of Random Forest.I’d be willing to bet that most people have used a decision tree, knowingly or not, at some point in their lives.
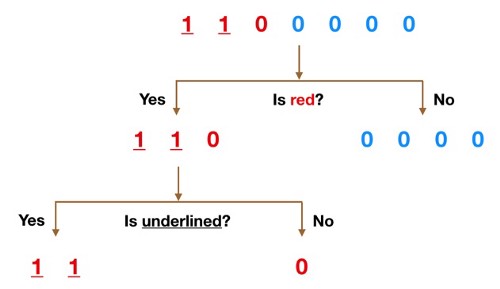
Color seems like a pretty obvious feature to split by as all but one of the 0s are blue. So we can use the question, “Is it red?” to split our first node. You can think of a node in a tree as the point where the path splits into two — observations that meet the criteria go down the Yes branch and ones that don’t go down the No branch. Now we can use the second feature and ask, “Is it underlined?” to make a second split.
Random Forest -
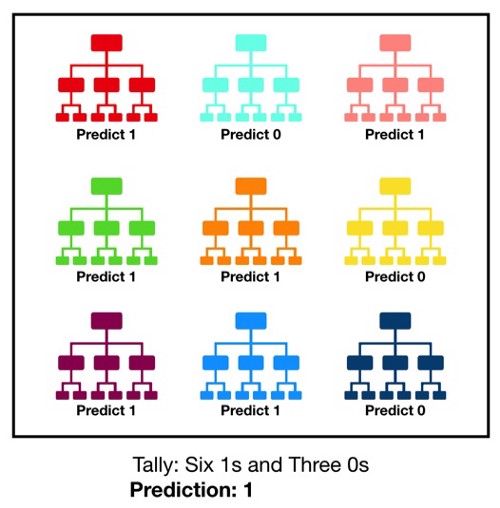
It consists of a large number of individual decision trees that operate as an ensemble. Each individual tree in the random forest spits out a class prediction and the class with the most votes becomes our model’s prediction. The higher the number of trees in the forest gives the high the accuracy results.
Let's Code :-
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_classification
Importing Random Forest Classifier to make a prediction and make_classification.
>>> X, y = make_classification(n_samples=1000, n_features=4,
... n_informative=2, n_redundant=0,
... random_state=0, shuffle=False)
>>> clf = RandomForestClassifier(max_depth=2, random_state=0)
>>> clf.fit(X, y)
RandomForestClassifier(...)
>>> print(clf.predict([[0, 0, 0, 0]]))
[1]
Now the last step is to fit our model and perform prediction.
This is a basic Random Forest classifier. In the next post, we will see the math behind the Random Forest classifier and its implementation from scratch. Thank you for being a patient reader. I hope this helps you in understanding Random forest well.
You can connect with me on LinkedIn for further tech conversation and networking.


